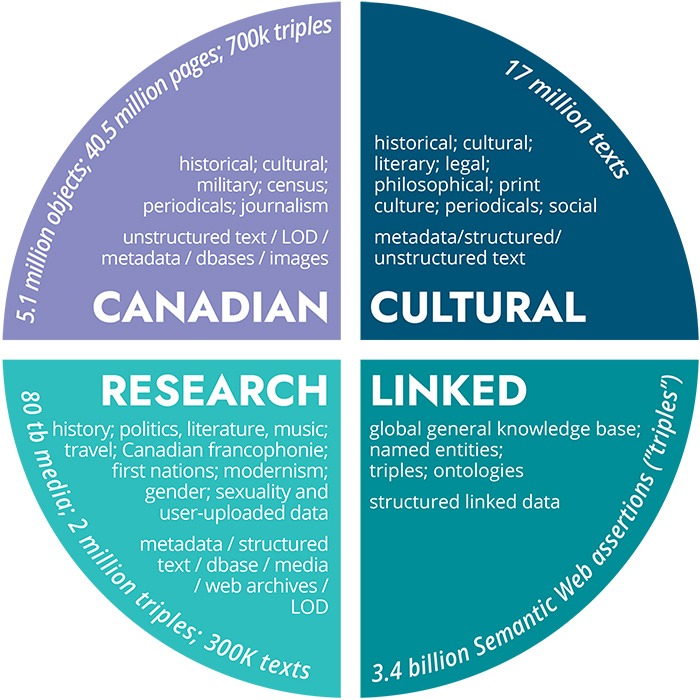
Datasets
Canadian
There are large bodies of content on the web related to Canadian culture and history: smaller sets of materials created by researchers, and large digitized collections held by memory institutions like Canadiana and Library and Archives Canada. We need better ways of accessing this content.
Cultural
There are also millions of books and periodicals, and other content that has been digitized by groups such as the Internet Archive, The Hathi Trust, and Project Gutenberg, as well as much native web content relevant to cultural research. LINCS will provide new ways of discovering and using these kinds of materials.
Linked
LINCS builds on much existing work that has been done towards an open, semantically structured web, from W3C standards and established ontologies to major community projects such as DBpedia and Wikidata. We aim to strengthen the Linked Open Data ecology through high quality open content and open-source tools.
Research
Datasets carefully curated by Canadian researchers are at the core of LINCS, which will mobilize this material and interlink it to other related content. The Source Datasets are rich and diverse, as are the Research Themes that will be developed by linking them.
These source datasets, with their various formats and origins, will work through a range of conversion processes in LINCS.