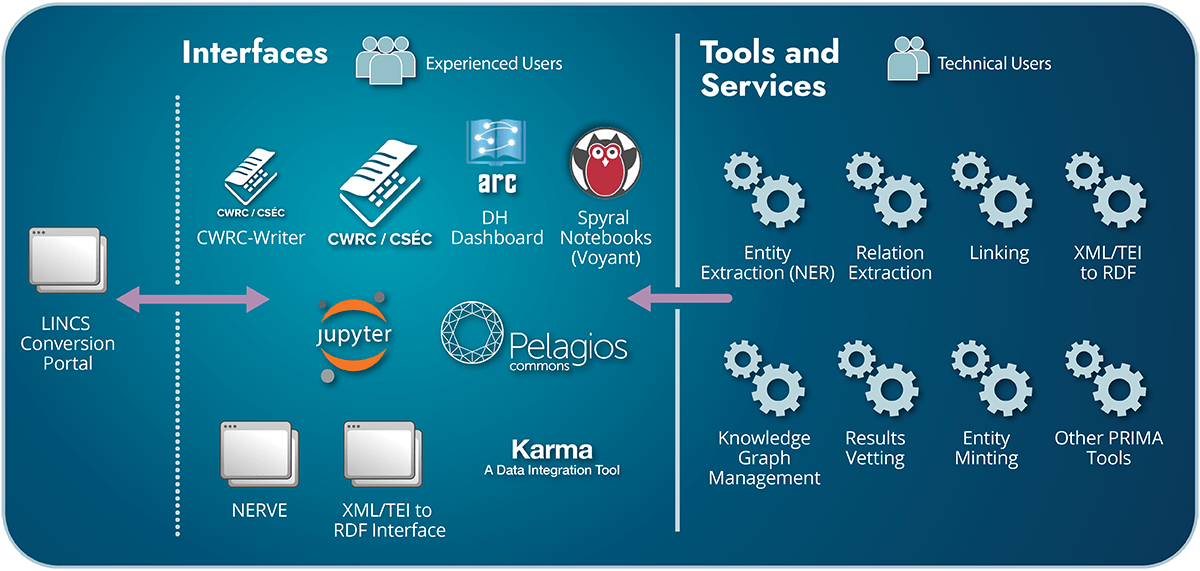
Conversion
LINCS will convert existing data into Linked Open Data by extracting linked data entities and relationships from heterogeneous datasets. The Conversion component involves both significant data conversion and tool adaptation. LINCS will support conversion from the most common formats used by the humanities research community: plain text (natural language), relational data (spreadsheets and databases), and semi-structured text (common XML schemas, including standard bibliographic formats and Text Encoding Initiatives).
The processes involved are:
- Detect entities at the heart of human history and culture;
- Disambiguate or link entities to one or more records of those entities (if available) stored in reference knowledge graphs from the Linked Open Data cloud;
- Create relationships based on ontologies between entities, either by mapping from the existing structure within the source materials or by using natural language processing and machine learning to detect them; and
- Validate the results to ensure sufficient precision, where resources and expertise exist.
Data Conversion
To quickly mobilize a large set of relevant data, LINCS prioritizes dataset conversion, starting with the most Linked Open Data–ready content. Core researcher datasets will receive the fullest processing, including human vetting. Others will be processed automatically, with confidence levels set for high precision to minimize false positives; the resulting millions of triples will make these materials immediately accessible, poised for vetting as researchers engage with them.
Conversion is of two types. The translation of a relational dataset into the Resource Description Framework (RDF) format of the Semantic Web maps from existing structures and points back to an active or archived source dataset. The extraction of Linked Open Data from a dataset comprised of natural or semi-structured language creates RDF that points back to the source on the web. In both cases, LINCS data conversion tools will track the provenance of the data for scholarly purposes.
Tool Adaptation
LINCS adopts standard algorithms for natural language processing (NLP) and entity matching for its conversion processes and tools, and will build on methods used by other large-scale Linked Open Data conversion projects including Linked Data for Production. Existing tools and processes will be adapted to convert datasets to Semantic Web statements (triples that use RDF).
LINCS will build on award-winning algorithms developed in Alberta that perform named entity recognition (NER) and named entity disambiguation (NED) with respect to one or more project knowledge graphs, incorporate hand-tagged datasets as training data for the models, and provide an interface for tuning parameters. LINCS conversion tools will be generic, modular, and work with several open-source algorithms. LINCS will also adopt or adapt several existing workflows and tools for data cleanup and vetting, including interfaces suitable for subject matter experts.